

















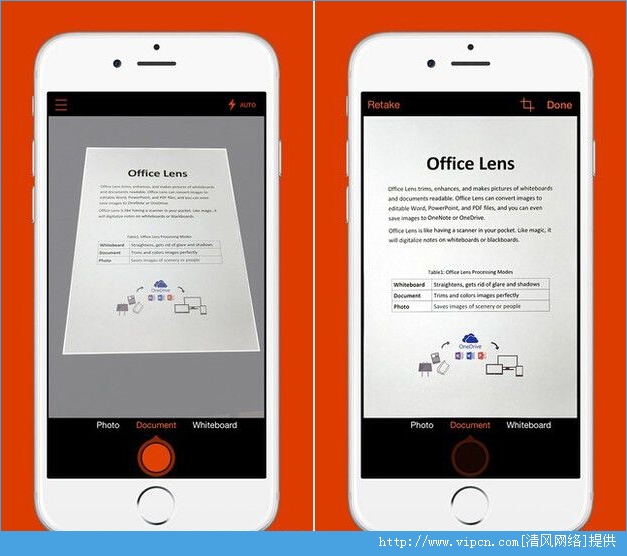
Office Lens是一款微型扫描仪办公软件,该软件最大的特点是OCR光学字符识别功能,那么这样的一款软件到底是如何诞生的呢?下面清风小编就和大家具体来说明下。
把手机摄像头对准菜单上的法语菜名,屏幕上实时显示出翻译好的中文菜名;将全世界图书馆的藏书转化为电子书;街景车游走于大街小巷,拍摄街景的同时也从街景图像中自动提取文字标识,让地图信息更丰富更准确……这些场景的背后有一个共同的关键技术――OCR (Optical Character Recognition),光学字符识别。 OCR让电脑“读”懂世界 鼠标发明人Douglas Engelbart曾经针对人工智能的简称AI提出了另一个理念――Augmented Intelligence,增强智能。在他看来,人已经足够聪明,我们无需再去复制人类,而是可以从更加实用的角度,将人类的智能进一步延伸,让机器去增强人的智能。 智能眼镜就是这样的产品,去超市的时候带上一副,看到心仪商品上的文字,自动搜索出详细信息:生产商情况、在不同电商平台的价格等等。让智能眼镜读懂文字的正是OCR技术。OCR本质上是利用光学设备去捕获图像,今天可以是手机、照相机,未来可以是智能眼镜、可穿戴设备等,就像人的眼睛一样,只要有文字,就去认出来。 我们也可以设想一下OCR在未来工作中的应用场景:每次工作会议后,无需再把白板上的讨论内容抄写下来,然后群发邮件布置任务,只要将白板用手机等智能设备拍照留存,系统便能自动识别并分检出相关人员的后续工作,并将待办事项自动存放到各自的电子日历中。 事实上,我们已经向这个场景迈进了一步,微软前不久推出的Office Lens应用,已经可以通过视觉计算技术自动对图像进行清理并把它保存到OneNote,而OneNote中基于云端的OCR技术将对图片进行文字识别,随后你就可以拥有一个可编辑、可搜索的数字文件,为上述未来应用场景打下基础。微软几年前推出的手机应用Translator,除了支持文本和语音翻译外,还能用手机拍摄不同语言的菜单或指示牌,翻译结果立即浮现于原文之上。Office Lens和Translator这两款产品中的“中日韩”OCR核心技术就来自微软亚洲研究院的语音团队。![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片1](https://imgo.vipcn.com/img14/20154/2015479223725321.jpg)
![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片2](https://imgo.vipcn.com/img14/20154/2015479223858968.jpg) 从平板扫描仪到前端手机后端云 回过头来看,OCR技术经历了怎样的发展历程呢?早在20世纪50年代,IBM就开始利用OCR技术实现各类文档的数字化,早期的OCR设备庞大而复杂,只能处理干净背景下的某种印刷字体。20世纪80年代,平板扫描仪的诞生让OCR进入商用阶段,设备更为轻便灵巧,可以处理的字体数量也增多,但对文字的背景要求仍然很高,需要很好的成像质量。 平板扫描仪对印刷体文本的识别率在20世纪90年代就已经达到99%以上,可谓OCR应用迎来的第一个高潮。当时最著名事件是谷歌数字图书馆,谷歌还申请了图书扫描专利,实现了批量化的高速扫描。在此期间,手写字体的识别也在并行发展,被广泛用于邮件分拣、支票分类、手写表格数字化等领域。 这样的成就一度让大家误以为OCR技术已经登峰造极,但从21世纪开始,准确地说是自从2004年拥有300万像素摄像头的智能手机诞生之日起,这一情况发生了根本改变。越来越多的人随手拿起手机拍摄所看到的事物和场景,而此类自然场景中的文字识别难度远远高于平板扫描仪时期,即便是印刷字体,也不能得到很高的识别率,更别说手写体了。学术界因此将自然场景中的文字识别作为全新的课题来对待。 与此同时,云计算、大数据以及通讯网络的快速发展,实现了智能手机的24小时在线,前端采用手机摄像头进行文字捕捉,后端可以对其进行实时分析和处理,二者的结合让OCR的未来应用模式充满想象。因此,对OCR的研究再度成为学术界的焦点,无论是前端识别技术还是后端的关联应用领域,都有着无限可能。微软亚洲研究院的研究员们,也非常有幸加入了这个大潮。 自然场景下的文字检测获突破性进展 自然场景图像中的文字识别大大难于扫描仪图像中的文字识别,因为它具有极大的多样性和明显的不确定性。如文字中包含多种语言,每种语言含有多种字母,每个字母又可以有不同的大小、字体、颜色、亮度、对比度等;文字通常以文本行的形式存在,但文本行可能有不同的排列和对齐方式,横向、竖向、弯曲都有可能;因拍摄图像的随意性,图像中的文字区域还可能会产生变形(透视和仿射变换)、残缺、模糊断裂等现象。
从平板扫描仪到前端手机后端云 回过头来看,OCR技术经历了怎样的发展历程呢?早在20世纪50年代,IBM就开始利用OCR技术实现各类文档的数字化,早期的OCR设备庞大而复杂,只能处理干净背景下的某种印刷字体。20世纪80年代,平板扫描仪的诞生让OCR进入商用阶段,设备更为轻便灵巧,可以处理的字体数量也增多,但对文字的背景要求仍然很高,需要很好的成像质量。 平板扫描仪对印刷体文本的识别率在20世纪90年代就已经达到99%以上,可谓OCR应用迎来的第一个高潮。当时最著名事件是谷歌数字图书馆,谷歌还申请了图书扫描专利,实现了批量化的高速扫描。在此期间,手写字体的识别也在并行发展,被广泛用于邮件分拣、支票分类、手写表格数字化等领域。 这样的成就一度让大家误以为OCR技术已经登峰造极,但从21世纪开始,准确地说是自从2004年拥有300万像素摄像头的智能手机诞生之日起,这一情况发生了根本改变。越来越多的人随手拿起手机拍摄所看到的事物和场景,而此类自然场景中的文字识别难度远远高于平板扫描仪时期,即便是印刷字体,也不能得到很高的识别率,更别说手写体了。学术界因此将自然场景中的文字识别作为全新的课题来对待。 与此同时,云计算、大数据以及通讯网络的快速发展,实现了智能手机的24小时在线,前端采用手机摄像头进行文字捕捉,后端可以对其进行实时分析和处理,二者的结合让OCR的未来应用模式充满想象。因此,对OCR的研究再度成为学术界的焦点,无论是前端识别技术还是后端的关联应用领域,都有着无限可能。微软亚洲研究院的研究员们,也非常有幸加入了这个大潮。 自然场景下的文字检测获突破性进展 自然场景图像中的文字识别大大难于扫描仪图像中的文字识别,因为它具有极大的多样性和明显的不确定性。如文字中包含多种语言,每种语言含有多种字母,每个字母又可以有不同的大小、字体、颜色、亮度、对比度等;文字通常以文本行的形式存在,但文本行可能有不同的排列和对齐方式,横向、竖向、弯曲都有可能;因拍摄图像的随意性,图像中的文字区域还可能会产生变形(透视和仿射变换)、残缺、模糊断裂等现象。![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片3](https://imgo.vipcn.com/img14/20154/2015479223827401.jpg) 与传统 OCR 技术中的扫描文档图像相比,自然场景图像的背景更为复杂。如文字可能不是写在平面上而是在曲面上;文字区域附近有非常复杂的纹理和噪声;图像中的非文字区域有着跟文字区域非常相似的纹理,比如窗户、树叶、栅栏、砖墙等。这些复杂背景会极大增加误检率。 由于自然场景下的文字识别难度大,微软亚洲研究院团队对相关技术和算法进行了针对性的优化和创新,从三个方面对文本检测技术进行了改进,并取得突破。通常,OCR识别的步骤可以分为两步:首先是文本检测(Text detection),将文字从图片中提取出来;然后,对文本进行识别(Recognition),此次的突破主要是在文本检测环节的两个子阶段。 阶段①:采用新算法,检测准确高效 一个字母或文字通常可以分为若干个连通区域,如o就拥有一个连通区域,i则拥有两个连通区域,文本检测首先要从图像中切割出可能存在的文字,即候选连通区域,然后再对其进行文字/非文字分类。 在确定候选连通区域阶段,微软亚洲研究院团队在传统检测方法ER(Extremal Region,极值区域)和MSER(Maximally Stable Extremal Region,最大平稳极值区域)基础之上创新地采用了对比极值区域CER(Contrasting Extremal Region),CER是跟周围的背景有一定对比度的极值区域,这个对比度至少要强到能够被人眼感知到,在低对比度的图像上比MSER效果更好,而且获得的候选连通区域数量远小于ER,候选范围大大缩小,提高了算法的效率。 为了提高所获得的候选连通区域的质量,微软亚洲研究院团队决定增加一个算法环节去增强CER。尤其在图像模糊、分辨率低或者噪声较多时,提取出来的CER有可能会含有冗余像素或者噪声,这些冗余像素或者噪声的存在会使得后面的文字/非文字分类问题变得更为复杂。 采用基于感知的光照不变(Perception-based Illumination Invariant, PII)颜色空间中的颜色信息去增强CER可算是此次算法优化的另一个创新之举,利用颜色信息尽可能滤除CER中的冗余像素或者噪声,从而得到Color-enhanced CER。该颜色空间具有视觉感知一致性,而且对光照不敏感,更接近人眼对颜色的判断。 在实际操作中,并不是每个CER都需要通过颜色信息来增强,因为有很多CER本身颜色均匀,没有噪声,尤其是在图片质量很高的时候。因此,在对CER进行增强操作之前我们会先判断该CER是否需要增强操作,以减少不必要的计算复杂度。
与传统 OCR 技术中的扫描文档图像相比,自然场景图像的背景更为复杂。如文字可能不是写在平面上而是在曲面上;文字区域附近有非常复杂的纹理和噪声;图像中的非文字区域有着跟文字区域非常相似的纹理,比如窗户、树叶、栅栏、砖墙等。这些复杂背景会极大增加误检率。 由于自然场景下的文字识别难度大,微软亚洲研究院团队对相关技术和算法进行了针对性的优化和创新,从三个方面对文本检测技术进行了改进,并取得突破。通常,OCR识别的步骤可以分为两步:首先是文本检测(Text detection),将文字从图片中提取出来;然后,对文本进行识别(Recognition),此次的突破主要是在文本检测环节的两个子阶段。 阶段①:采用新算法,检测准确高效 一个字母或文字通常可以分为若干个连通区域,如o就拥有一个连通区域,i则拥有两个连通区域,文本检测首先要从图像中切割出可能存在的文字,即候选连通区域,然后再对其进行文字/非文字分类。 在确定候选连通区域阶段,微软亚洲研究院团队在传统检测方法ER(Extremal Region,极值区域)和MSER(Maximally Stable Extremal Region,最大平稳极值区域)基础之上创新地采用了对比极值区域CER(Contrasting Extremal Region),CER是跟周围的背景有一定对比度的极值区域,这个对比度至少要强到能够被人眼感知到,在低对比度的图像上比MSER效果更好,而且获得的候选连通区域数量远小于ER,候选范围大大缩小,提高了算法的效率。 为了提高所获得的候选连通区域的质量,微软亚洲研究院团队决定增加一个算法环节去增强CER。尤其在图像模糊、分辨率低或者噪声较多时,提取出来的CER有可能会含有冗余像素或者噪声,这些冗余像素或者噪声的存在会使得后面的文字/非文字分类问题变得更为复杂。 采用基于感知的光照不变(Perception-based Illumination Invariant, PII)颜色空间中的颜色信息去增强CER可算是此次算法优化的另一个创新之举,利用颜色信息尽可能滤除CER中的冗余像素或者噪声,从而得到Color-enhanced CER。该颜色空间具有视觉感知一致性,而且对光照不敏感,更接近人眼对颜色的判断。 在实际操作中,并不是每个CER都需要通过颜色信息来增强,因为有很多CER本身颜色均匀,没有噪声,尤其是在图片质量很高的时候。因此,在对CER进行增强操作之前我们会先判断该CER是否需要增强操作,以减少不必要的计算复杂度。![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片4](https://imgo.vipcn.com/img14/20154/2015479223885139.jpg)
![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片5](https://imgo.vipcn.com/img14/20154/2015479223970279.jpg) 阶段②:创新分类,检测更高质 当获得了高质量的候选连通区域,就需要对其中的字符进行分辨,确定其是否为文字或非文字,微软亚洲研究院团队创新地提出了一套基于浅层神经网络的文字/非文字分类算法,比以往的算法更加有效。 该算法根据文字本身的特性采用分治策略将原始问题空间划分为5个子空间,每个子空间对应一类文字样本,分别命名为Long类,Thin类,Fill类,Square-large类和 Square-small类(如下图所示),于是每个候选连通区域被划分到这5类中的一种。 text-space在每个子空间中,微软亚洲研究院团队创新地利用无歧义学习策略训练一个相应的浅层神经网络,作为该子空间的文字/非文字分类器,我们可以将该神经网络看作是一个黑盒子,在经过大量学习之后,它便能较为准确的将文字与非文字分类。 每次分类动作包括两个阶段――预剪枝(Pre-pruning)阶段和验证(Verification)阶段。在预剪枝阶段,分类器的任务是尽可能滤除无歧义的非文字候选连通区域;在验证阶段,则通过引入更多信息来消除孤立连通区域的歧义性,从而进一步滤除有歧义的非文字候选连通区域。
阶段②:创新分类,检测更高质 当获得了高质量的候选连通区域,就需要对其中的字符进行分辨,确定其是否为文字或非文字,微软亚洲研究院团队创新地提出了一套基于浅层神经网络的文字/非文字分类算法,比以往的算法更加有效。 该算法根据文字本身的特性采用分治策略将原始问题空间划分为5个子空间,每个子空间对应一类文字样本,分别命名为Long类,Thin类,Fill类,Square-large类和 Square-small类(如下图所示),于是每个候选连通区域被划分到这5类中的一种。 text-space在每个子空间中,微软亚洲研究院团队创新地利用无歧义学习策略训练一个相应的浅层神经网络,作为该子空间的文字/非文字分类器,我们可以将该神经网络看作是一个黑盒子,在经过大量学习之后,它便能较为准确的将文字与非文字分类。 每次分类动作包括两个阶段――预剪枝(Pre-pruning)阶段和验证(Verification)阶段。在预剪枝阶段,分类器的任务是尽可能滤除无歧义的非文字候选连通区域;在验证阶段,则通过引入更多信息来消除孤立连通区域的歧义性,从而进一步滤除有歧义的非文字候选连通区域。























盖楼回复 X
(您的评论需要经过审核才能显示)