![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片1](https://imgo.vipcn.com/img14/20154/2015479223725321.jpg)
![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片2](https://imgo.vipcn.com/img14/20154/2015479223858968.jpg)
从平板扫描仪到前端手机后端云 回过头来看,OCR技术经历了怎样的发展历程呢?早在20世纪50年代,IBM就开始利用OCR技术实现各类文档的数字化,早期的OCR设备庞大而复杂,只能处理干净背景下的某种印刷字体。20世纪80年代,平板扫描仪的诞生让OCR进入商用阶段,设备更为轻便灵巧,可以处理的字体数量也增多,但对文字的背景要求仍然很高,需要很好的成像质量。 平板扫描仪对印刷体文本的识别率在20世纪90年代就已经达到99%以上,可谓OCR应用迎来的第一个高潮。当时最著名事件是谷歌数字图书馆,谷歌还申请了图书扫描专利,实现了批量化的高速扫描。在此期间,手写字体的识别也在并行发展,被广泛用于邮件分拣、支票分类、手写表格数字化等领域。 这样的成就一度让大家误以为OCR技术已经登峰造极,但从21世纪开始,准确地说是自从2004年拥有300万像素摄像头的智能手机诞生之日起,这一情况发生了根本改变。越来越多的人随手拿起手机拍摄所看到的事物和场景,而此类自然场景中的文字识别难度远远高于平板扫描仪时期,即便是印刷字体,也不能得到很高的识别率,更别说手写体了。学术界因此将自然场景中的文字识别作为全新的课题来对待。 与此同时,云计算、大数据以及通讯网络的快速发展,实现了智能手机的24小时在线,前端采用手机摄像头进行文字捕捉,后端可以对其进行实时分析和处理,二者的结合让OCR的未来应用模式充满想象。因此,对OCR的研究再度成为学术界的焦点,无论是前端识别技术还是后端的关联应用领域,都有着无限可能。微软亚洲研究院的研究员们,也非常有幸加入了这个大潮。 自然场景下的文字检测获突破性进展 自然场景图像中的文字识别大大难于扫描仪图像中的文字识别,因为它具有极大的多样性和明显的不确定性。如文字中包含多种语言,每种语言含有多种字母,每个字母又可以有不同的大小、字体、颜色、亮度、对比度等;文字通常以文本行的形式存在,但文本行可能有不同的排列和对齐方式,横向、竖向、弯曲都有可能;因拍摄图像的随意性,图像中的文字区域还可能会产生变形(透视和仿射变换)、残缺、模糊断裂等现象。
![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片3](https://imgo.vipcn.com/img14/20154/2015479223827401.jpg)
与传统 OCR 技术中的扫描文档图像相比,自然场景图像的背景更为复杂。



















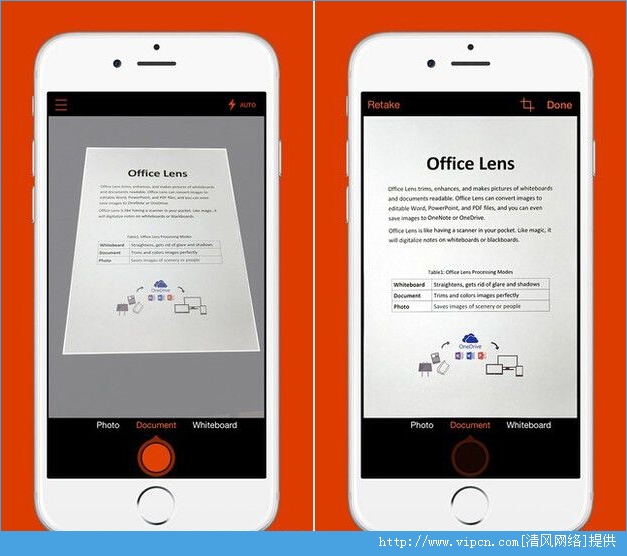























盖楼回复 X
(您的评论需要经过审核才能显示)