

















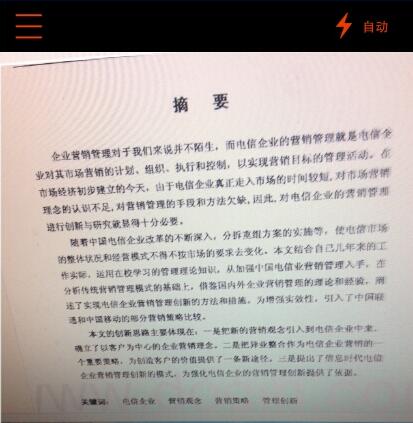
如文字可能不是写在平面上而是在曲面上;文字区域附近有非常复杂的纹理和噪声;图像中的非文字区域有着跟文字区域非常相似的纹理,比如窗户、树叶、栅栏、砖墙等。这些复杂背景会极大增加误检率。 由于自然场景下的文字识别难度大,微软亚洲研究院团队对相关技术和算法进行了针对性的优化和创新,从三个方面对文本检测技术进行了改进,并取得突破。通常,OCR识别的步骤可以分为两步:首先是文本检测(Text detection),将文字从图片中提取出来;然后,对文本进行识别(Recognition),此次的突破主要是在文本检测环节的两个子阶段。 阶段①:采用新算法,检测准确高效 一个字母或文字通常可以分为若干个连通区域,如o就拥有一个连通区域,i则拥有两个连通区域,文本检测首先要从图像中切割出可能存在的文字,即候选连通区域,然后再对其进行文字/非文字分类。 在确定候选连通区域阶段,微软亚洲研究院团队在传统检测方法ER(Extremal Region,极值区域)和MSER(Maximally Stable Extremal Region,最大平稳极值区域)基础之上创新地采用了对比极值区域CER(Contrasting Extremal Region),CER是跟周围的背景有一定对比度的极值区域,这个对比度至少要强到能够被人眼感知到,在低对比度的图像上比MSER效果更好,而且获得的候选连通区域数量远小于ER,候选范围大大缩小,提高了算法的效率。 为了提高所获得的候选连通区域的质量,微软亚洲研究院团队决定增加一个算法环节去增强CER。尤其在图像模糊、分辨率低或者噪声较多时,提取出来的CER有可能会含有冗余像素或者噪声,这些冗余像素或者噪声的存在会使得后面的文字/非文字分类问题变得更为复杂。 采用基于感知的光照不变(Perception-based Illumination Invariant, PII)颜色空间中的颜色信息去增强CER可算是此次算法优化的另一个创新之举,利用颜色信息尽可能滤除CER中的冗余像素或者噪声,从而得到Color-enhanced CER。该颜色空间具有视觉感知一致性,而且对光照不敏感,更接近人眼对颜色的判断。 在实际操作中,并不是每个CER都需要通过颜色信息来增强,因为有很多CER本身颜色均匀,没有噪声,尤其是在图片质量很高的时候。因此,在对CER进行增强操作之前我们会先判断该CER是否需要增强操作,以减少不必要的计算复杂度。![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片4](https://imgo.vipcn.com/img14/20154/2015479223885139.jpg)
![Office Lens是怎样诞生的?Office Lens由来分析[多图]图片5](https://imgo.vipcn.com/img14/20154/2015479223970279.jpg) 阶段②:创新分类,检测更高质 当获得了高质量的候选连通区域,就需要对其中的字符进行分辨,确定其是否为文字或非文字,微软亚洲研究院团队创新地提出了一套基于浅层神经网络的文字/非文字分类算法,比以往的算法更加有效。
阶段②:创新分类,检测更高质 当获得了高质量的候选连通区域,就需要对其中的字符进行分辨,确定其是否为文字或非文字,微软亚洲研究院团队创新地提出了一套基于浅层神经网络的文字/非文字分类算法,比以往的算法更加有效。
阶段②:创新分类,检测更高质 当获得了高质量的候选连通区域,就需要对其中的字符进行分辨,确定其是否为文字或非文字,微软亚洲研究院团队创新地提出了一套基于浅层神经网络的文字/非文字分类算法,比以往的算法更加有效。
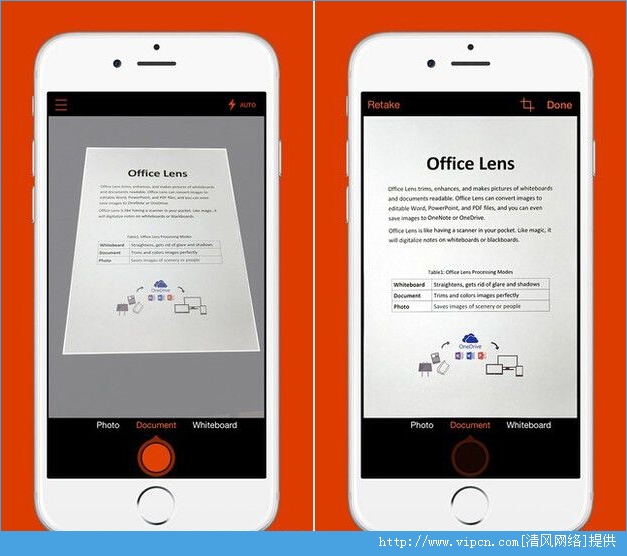























盖楼回复 X
(您的评论需要经过审核才能显示)